|
특성
|
K-means
|
Hierarchical
|
DBSCAN
|
|
클러스터 개수
|
사전 지정 필요
|
나중에 결정
|
자동 결정
|
|
클러스터 형태
|
구형만 가능
|
제한적
|
임의 형태
|
|
노이즈 처리
|
불가능
|
어려움
|
탁월함
|
|
계산 복잡도
|
O(n)
|
O(n³)
|
O(n log n)
|
|
하이퍼파라미터
|
k값
|
linkage 방법
|
eps, min_samples
|
계층적 군집화(Hierarchical Clustering)란?
데이터를 계층적 구조로 군집화하는 방법
1. 응집형(Agglomerative) Bottom up 방식
- 각 데이터를 개별 클러스터로 시작
- 가까운 클러스터들을 순차적 합병
- 최종 하나 클러스터
- 초기화 > 거리 행렬 계산 > 합병 > 업데이트 > 반복
2. 분할형(Divisive) Top down 방식
- 모든 데이터를 하나의 클러스터로 시작
- 먼 클러스터들을 순차적 분할
- 최종 개별 클러스터
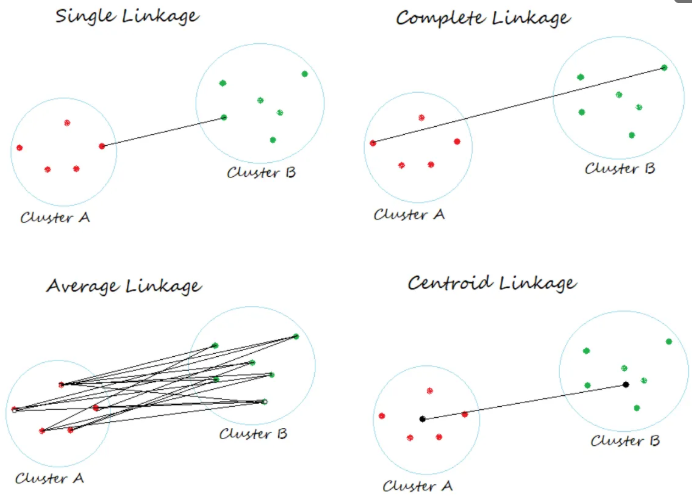
클러스터 간 거리 측정 방법(Linkage Methods)
1. 최단 연결법(Single Linkage)
두 클러스터에서 가장 가까운 두 점 사이의 거리
2. 최장 연결법(Complete Linkage)
두 클러스터에서 가장 먼 두 점 사이의 거리
3. 평균 연결법(Average Linkage)
두 클러스터의 모든 점 쌍 거리의 평균
4. 와드 연결법(Wark Linkage)
클러스터 내 분산의 증가량 최소화
덴드로그램(Dendrogram)이란?
- 계층적 군집화의 핵심 결과물
- 클러스터 형성 과정을 트리 구조로 시각화
1. 세로축(Height/Distance)
클러스터 간 거리
2. 가로축(Data Points)
개별 데이터 포인트
3. 가지치기(Cutting the Tree)
원하는 높이에서 수평선 그어 클러스터 개수 결정
[코드]
1단계
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import load_iris, make_blobs
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import AgglomerativeClustering
from scipy.cluster.hierarchy import dendrogram, linkage, fcluster
from scipy.spatial.distance import pdist
import warnings
warnings.filterwarnings('ignore')
# 한글 폰트 설정
plt.rcParams['font.family'] = 'Malgun Gothic'
plt.rcParams['axes.unicode_minus'] = False
# 데이터 준비 - Iris 데이터와 합성 데이터 비교
iris = load_iris()
X_iris = iris.data
y_iris = iris.target
# 표준화
scaler = StandardScaler()
X_iris_scaled = scaler.fit_transform(X_iris)2단계: 클러스터링 수행
plt.figure(figsize=(10, 10))
linkage_matrix = linkage(X_iris_scaled, method='ward')
# 덴드로그램 그리기
plt.subplot(2,1, 1)
dendrogram(linkage_matrix, truncate_mode='level', p=5)
plt.xlabel('Sample Index')
plt.ylabel('Distance')
# 클러스터링 결과 시각화
plt.subplot(2, 1, 2)
cluster_labels = fcluster(linkage_matrix, t=3, criterion='maxclust')
scatter = plt.scatter(X_iris_scaled[:, 0], X_iris_scaled[:, 1],
c=cluster_labels, cmap='viridis', alpha=0.7)
plt.ylabel('Feature 2')
plt.colorbar(scatter)
plt.tight_layout()
plt.show()DBSCAN(Density-Based Spatial Clustering of Applications with Noise)이란?
밀도 기반 클러스터링
밀도 낮은 지역 = 노이즈
(유리) 노이즈가 많을때, 불규칙 할때, 개수 모를때, 기하학적 패턴(ex. 자율주행)
(한계) 다양한 밀도일때, 하이퍼 파라미터 값에 따라 결과가 많이 달라짐.
[핵심 용어]
두개의 하이퍼 파라미터
1. Eps(Epsilon): 특정 데이터 중심으로 몇 개의 데이터 포인트가 있는지
- 너무 작으면: 대부분의 점이 노이즈로 분류
- 너무 크면: 모든 점이 하나의 클러스터로 통합
- 적절한 값: 의미 있는 클러스터와 노이즈의 구분
2. MinPts(Minimun Points): Eps 내 존재하는 포인트들이 같은 클러스터로 묶이기 위한 최소한의 점 갯수
- 일반적 가이드라인
- 데이터 셋의 크기가 클 수록 MinPts 값을 크게 잡는 것이 유리
- 데이터에 Noise가 많은 경우에도 MinPts를 크게 잡는 것이 유리
- Rule of thumb
- 데이터포인트의 차원 D, MinPts ≥ D+1
- MinPts = 2 * D (보통O, 항상 X)
데이터 포인트
1. Core Point: Eps > MinPts
2. Border Point: Eps < MinPts, Core Point가 Eps 이내에 존재O
3. Noise Point: Eps < MinPts, Core Point가 Eps 이내에 존재X
[과정]
1단계. 임의의 데이터 포인트 선택
2단계. 선택한 데이터와 Eps 거리 내에 있는 모든 데이터 포인트 찾기
3단계. Eps > MinPts 이면, 하나의 클러스터로 지정(초기 포인트 = Core Point)(아닐시 Noise Point)
4단계. 클러스터 내 Core Point 존재시, 그 점의 클러스터도 동일시 간주
5단계: 클러스터 모든 점에 대해 위 과정 방반
6단계: 모든 점이 Core Point / Border Point / Noise Point 정해지면 스탑
[코드]
1단계: 다양한 데이터셋 생성
데이터셋별 특성 이해
- Moons: 초승달 모양의 비볼록 클러스터 → K-means가 어려워하는 형태
- Circles: 동심원 구조 → 중심 기반 알고리즘의 한계 테스트
- Blobs: 구형 클러스터 → 전통적 클러스터링에 적합한 형태
- Anisotropic: 타원형으로 변형된 클러스터 → 방향성이 있는 데이터
데이터 생성 함수 파라미터
- noise: 데이터에 추가할 잡음의 정도 (0.05~0.1이 적절)
- factor: Circles에서 내부원과 외부원의 비율
- cluster_std: Blobs에서 클러스터 내 표준편차
- transformation matrix: 선형 변환을 통한 비등방성 클러스터 생성
from sklearn.cluster import DBSCAN
from sklearn.datasets import make_moons, make_circles, make_blobs
np.random.seed(42)
# 데이터셋 생성
datasets = {
'Moons': make_moons(n_samples=300, noise=0.1, random_state=42),
'Circles': make_circles(n_samples=300, noise=0.05, factor=0.5, random_state=42),
'Blobs': make_blobs(n_samples=300, centers=4, n_features=2, random_state=42, cluster_std=0.8),
'Anisotropic': make_blobs(n_samples=300, centers=3, n_features=2, random_state=42, cluster_std=1.5)
}
# 비등방성 데이터 변환
X_aniso, y_aniso = datasets['Anisotropic']
transformation = np.array([[0.6, -0.6], [-0.4, 0.8]])
X_aniso = np.dot(X_aniso, transformation)
datasets['Anisotropic'] = (X_aniso, y_aniso)
# 데이터셋 미리보기
plt.figure(figsize=(16, 4))
for i, (name, (X, y)) in enumerate(datasets.items()):
plt.subplot(1, 4, i+1)
plt.scatter(X[:, 0], X[:, 1], c=y, cmap='viridis', alpha=0.7, s=30)
plt.title(f'{name} Dataset')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
print("=== 생성된 데이터셋 특성 ===")
for name, (X, y) in datasets.items():
print(f"{name}: {X.shape[0]}개 샘플, {len(np.unique(y))}개 클러스터")
2단계: 모델 학습 및 결과 계산
eps 값 설정 전략
- 데이터 스케일 고려: 각 데이터셋의 좌표 범위에 맞는 eps 선택
- 클러스터 형태 반영: 복잡한 형태일수록 더 큰 eps 값 필요
- 경험적 조정: K-distance 그래프나 시행착오를 통한 최적화
모델 학습 과정 모니터링
- K-means 수렴: n_iter를 통해 알고리즘이 안정적으로 수렴했는지 확인
- DBSCAN 결과: 클러스터 개수와 노이즈 비율로 결과의 타당성 평가
- 성능 지표: 실루엣 스코어로 클러스터 품질 정량화
결과 저장 구조
- 원본 데이터: 시각화를 위한 X, y_true 보존
- 모델 결과: 라벨과 중심점 등 클러스터링 결과 저장
- 성능 지표: 정량적 비교를 위한 점수 기록
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
# 데이터셋별 최적 eps 값 (경험적으로 설정)
eps_values = {'Moons': 0.3, 'Circles': 0.2, 'Blobs': 0.3, 'Anisotropic': 0.4}
# 모든 데이터셋에 대해 클러스터링 수행
clustering_results = {}
comparison_results = []
for name, (X, y_true) in datasets.items():
print(f"\n=== {name} 데이터셋 처리 중 ===")
# 1. K-means 클러스터링
n_clusters = len(np.unique(y_true))
print(f"실제 클러스터 수: {n_clusters}")
kmeans = KMeans(n_clusters=n_clusters, random_state=42, n_init=10)
kmeans_labels = kmeans.fit_predict(X)
kmeans_centers = kmeans.cluster_centers_
print(f"K-means 완료 - 반복 횟수: {kmeans.n_iter_}")
# 2. DBSCAN 클러스터링
eps = eps_values[name]
dbscan = DBSCAN(eps=eps, min_samples=5)
dbscan_labels = dbscan.fit_predict(X)
# DBSCAN 결과 분석
n_clusters_dbscan = len(set(dbscan_labels)) - (1 if -1 in dbscan_labels else 0)
n_noise = list(dbscan_labels).count(-1)
unique_clusters = set(dbscan_labels) - {-1} # 노이즈 제외한 클러스터
print(f"DBSCAN 완료 - 발견된 클러스터: {n_clusters_dbscan}개, 노이즈 포인트: {n_noise}개")
# 3. 성능 지표 계산 (가능한 경우)
# 실루엣 스코어 계산
if len(set(kmeans_labels)) >= 2:
kmeans_silhouette = silhouette_score(X, kmeans_labels)
else:
kmeans_silhouette = -1
if n_clusters_dbscan >= 2:
non_noise_mask = dbscan_labels != -1
if np.sum(non_noise_mask) >= 2:
dbscan_silhouette = silhouette_score(X[non_noise_mask], dbscan_labels[non_noise_mask])
else:
dbscan_silhouette = -1
else:
dbscan_silhouette = -1
print(f"실루엣 스코어 - K-means: {kmeans_silhouette:.3f}, DBSCAN: {dbscan_silhouette:.3f}")
# 결과 저장
clustering_results[name] = {
'X': X,
'y_true': y_true,
'kmeans_labels': kmeans_labels,
'kmeans_centers': kmeans_centers,
'kmeans_silhouette': kmeans_silhouette,
'dbscan_labels': dbscan_labels,
'dbscan_silhouette': dbscan_silhouette,
'eps': eps
}
# 비교 결과 정리
comparison_results.append({
'Dataset': name,
'Original_clusters': len(np.unique(y_true)),
'KMeans_clusters': n_clusters,
'KMeans_silhouette': kmeans_silhouette,
'DBSCAN_clusters': n_clusters_dbscan,
'DBSCAN_noise': n_noise,
'DBSCAN_silhouette': dbscan_silhouette,
'Noise_ratio': f"{n_noise/len(X)*100:.1f}%"
})3단계: 클러스터링 결과 시각화
K-means 시각화 특징
- 중심점 표시: 빨간 X로 각 클러스터의 무게중심 시각화
- Voronoi 분할: 중심점을 기준으로 한 영역 분할 확인
- 구형 가정: 원형 경계로 제한되는 클러스터 형태 관찰
DBSCAN 시각화 특징
- 밀도 기반 경계: 데이터 밀도에 따른 자연스러운 클러스터 경계
- 노이즈 탐지: 고립된 점들의 자동 식별 및 표시
- 형태 자유도: 초승달, 동심원 등 복잡한 형태도 정확히 포착
fig, axes = plt.subplots(4, 3, figsize=(18, 20))
fig.suptitle('K-means vs DBSCAN Comparison', fontsize=16, fontweight='bold')
# 각 데이터셋별로 시각화
for i, (name, results) in enumerate(clustering_results.items()):
X = results['X']
y_true = results['y_true']
kmeans_labels = results['kmeans_labels']
kmeans_centers = results['kmeans_centers']
dbscan_labels = results['dbscan_labels']
eps = results['eps']
# 1. 원본 데이터 시각화
scatter1 = axes[i, 0].scatter(X[:, 0], X[:, 1], c=y_true, cmap='viridis', alpha=0.7, s=50)
axes[i, 0].set_title(f'{name} - Original Data\n({len(np.unique(y_true))} true clusters)')
axes[i, 0].grid(True, alpha=0.3)
axes[i, 0].set_xlabel('Feature 1')
axes[i, 0].set_ylabel('Feature 2')
# 2. K-means 결과 시각화
scatter2 = axes[i, 1].scatter(X[:, 0], X[:, 1], c=kmeans_labels, cmap='viridis', alpha=0.7, s=50)
axes[i, 1].scatter(kmeans_centers[:, 0], kmeans_centers[:, 1],
c='red', marker='x', s=200, linewidths=3, label='Centroids')
axes[i, 1].set_title(f'{name} - K-means\n(Silhouette: {results["kmeans_silhouette"]:.3f})')
axes[i, 1].grid(True, alpha=0.3)
axes[i, 1].set_xlabel('Feature 1')
axes[i, 1].set_ylabel('Feature 2')
axes[i, 1].legend()
# 3. DBSCAN 결과 시각화
unique_labels = set(dbscan_labels)
n_clusters_dbscan = len(unique_labels) - (1 if -1 in unique_labels else 0)
colors = plt.cm.Spectral(np.linspace(0, 1, len(unique_labels)))
for k, col in zip(unique_labels, colors):
if k == -1:
# 노이즈 포인트는 검은색 X로 표시
col = 'black'
marker = 'x'
alpha = 0.5
size = 30
else:
marker = 'o'
alpha = 0.7
size = 50
class_member_mask = (dbscan_labels == k)
xy = X[class_member_mask]
axes[i, 2].scatter(xy[:, 0], xy[:, 1], c=[col], marker=marker,
alpha=alpha, s=size)
axes[i, 2].set_title(f'{name} - DBSCAN (eps={eps})\n'
f'({n_clusters_dbscan} clusters, Silhouette: {results["dbscan_silhouette"]:.3f})')
axes[i, 2].grid(True, alpha=0.3)
axes[i, 2].set_xlabel('Feature 1')
axes[i, 2].set_ylabel('Feature 2')
plt.tight_layout()
plt.show()4단계: 정량적 분석
성능 비교 분석
- 클러스터 개수 정확도: DBSCAN이 데이터 특성에 더 적응적, 좀 애매한 부분은 정성적 분석을 통해 파라미터 조절이 필요
- 노이즈 탐지 능력: DBSCAN만이 이상치를 별도로 식별
- 형태 적응성: 복잡한 형태에서 DBSCAN이 압도적 우세
# 1-3단계: 비교 결과 정량적 분석
results_df = pd.DataFrame(comparison_results)
# 시각적 요약
fig, axes = plt.subplots(1, 2, figsize=(15, 5))
# 클러스터 개수 비교
x_pos = np.arange(len(results_df))
width = 0.25
axes[0].bar(x_pos - width, results_df['Original_clusters'], width,
label='Original', alpha=0.8, color='lightgreen')
axes[0].bar(x_pos, results_df['KMeans_clusters'], width,
label='K-means', alpha=0.8, color='skyblue')
axes[0].bar(x_pos + width, results_df['DBSCAN_clusters'], width,
label='DBSCAN', alpha=0.8, color='orange')
axes[0].set_xlabel('Dataset')
axes[0].set_ylabel('Number of Clusters')
axes[0].set_title('Cluster Count Comparison')
axes[0].set_xticks(x_pos)
axes[0].set_xticklabels(results_df['Dataset'], rotation=45)
axes[0].legend()
axes[0].grid(True, alpha=0.3)
# 노이즈 비율 분석
noise_ratios = [float(x.rstrip('%')) for x in results_df['Noise_ratio']]
axes[1].bar(results_df['Dataset'], noise_ratios, alpha=0.8, color='red')
axes[1].set_xlabel('Dataset')
axes[1].set_ylabel('Noise Ratio (%)')
axes[1].set_title('DBSCAN Noise Detection')
axes[1].tick_params(axis='x', rotation=45)
axes[1].grid(True, alpha=0.3)
# 각 막대 위에 수치 표시
for i, v in enumerate(noise_ratios):
axes[1].text(i, v + 0.5, f'{v:.1f}%', ha='center', va='bottom')
plt.tight_layout()
plt.show()차원 축소(PCA, t-SNE)
PCA(주성분 분석)이란?(Principal Component Analysis)
고차원 데이터를 저차원으로 변환하면서 원본 데이터의 분산을 최대한 보존하는 선형 차원 축소 기법
데이터의 분산이 가장 큰 방향(주성분)으로 새로운 축 설정
원본 데이터를 주성분들의 선형결합으로 표현
(장점) 정보 손실 최소화, 데이터 복잡도 감소, 차원의 저주 해소
(단점) 차원별 의미 사용 불가
[과정]
1단계: 분산을 최대한 보존하며 직교하는 새로운 축(기저)(첫번째) 찾기
2단계: 첫번째와 직교(독립)하면서 분산이 최대인 두번째 축 찾기
3단계: 기존 차원만큼 반복
4단계: 적당한 수의 주성분 선택
5단계: 새로운 차원에 대해 데이터 좌표변환(사영)
[코드1]
1단계: 필요한 라이브러리 불러오기
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_breast_cancer # 유방암 데이터셋 불러오기
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.cluster import KMeans2단계: 데이터셋 로드 및 표준화
# 유방암 데이터셋 로드
cancer = load_breast_cancer()
X = cancer.data # 30개의 특성 데이터
y = cancer.target # 타겟 데이터 (0: 악성, 1: 양성)
feature_names = cancer.feature_names # 특성 이름
# 데이터 표준화
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
print("유방암 원본 데이터셋의 차원 (샘플 수, 특성 수):", X.shape)
print("유방암 특성 이름 (일부):\n", feature_names[:5], "...") # 30개 중 5개만 출력
print("표준화된 데이터셋의 상위 5개 행:\n", pd.DataFrame(X_scaled, columns=feature_names).head())3단계: K-means 클러스터링 수행
# K-Means 클러스터링 객체 생성 (클러스터 2개)
kmeans = KMeans(n_clusters=2, random_state=42, n_init=10)
# K-Means 클러스터링 수행 및 클러스터 라벨 얻기
clusters = kmeans.fit_predict(X_scaled)4단계: K-means 결과 먼저 체크하기
# 원본 데이터와 클러스터 라벨을 포함하는 데이터프레임 생성
df_original_clusters = pd.DataFrame(X_scaled, columns=feature_names)
df_original_clusters['cluster'] = clusters
df_original_clusters['actual_target'] = y # 실제 진단 결과 (비교를 위해 추가)
# 원본 특성 ('mean radius' vs 'mean texture')으로 클러스터 시각화
plt.figure(figsize=(10, 6))
scatter = plt.scatter(df_original_clusters['mean radius'],
df_original_clusters['mean texture'],
c=df_original_clusters['cluster'],
cmap='viridis',
s=50,
alpha=0.8)
plt.xlabel('Mean Radius (Standardized)')
plt.ylabel('Mean Texture (Standardized)')
plt.title('K-Means Clusters on Original Features (Mean Radius vs. Mean Texture)')
plt.colorbar(scatter, label='Cluster Label')
plt.grid(True)
plt.show()
# 실제 진단 결과로 시각화 (비교)
plt.figure(figsize=(10, 6))
scatter_actual = plt.scatter(df_original_clusters['mean radius'],
df_original_clusters['mean texture'],
c=df_original_clusters['actual_target'],
cmap='viridis',
s=50,
alpha=0.8)
plt.xlabel('Mean Radius (Standardized)')
plt.ylabel('Mean Texture (Standardized)')
plt.title('Actual Diagnosis on Original Features (Mean Radius vs. Mean Texture)')
plt.colorbar(scatter_actual, label='Actual Diagnosis')
plt.grid(True)
plt.show()5단계: PCA 적용: 2개의 주성분으로 차원 축소
# PCA 객체 생성 (2개의 주성분으로 축소)
pca = PCA(n_components=2)
# PCA 적용
X_pca = pca.fit_transform(X_scaled)6단계: 주성분 분석 결과 확인해보기
components_df
가중치의 절댓값이 클수록 해당 특성이 주성분을 구성하는 데 더 큰 영향을 미친다
양수 가중치는 특성이 주성분과 같은 방향으로 변화할 때, 음수 가중치는 반대 방향으로 변화할 때 영향을 미친다
# 주성분(Principal Components)의 실제 값 (components_) 확인
# 각 행이 주성분이고, 각 열은 원본 특성(feature)에 대한 가중치
print("\n주성분 벡터 (원본 특성에 대한 가중치):\n", pca.components_)
# 데이터프레임으로 변환하여 보기 쉽게
components_df = pd.DataFrame(pca.components_,
columns=feature_names,
index=['Principal Component 1', 'Principal Component 2'])
# 각 주성분에 대해 가장 큰 영향을 미치는 특성들을 시각화 (선택적)
plt.figure(figsize=(12, 6))
# 첫 번째 주성분 (PC1)
plt.subplot(1, 2, 1)
components_df.loc['Principal Component 1'].plot(kind='bar')
plt.title('Contribution of Original Features to Principal Component 1')
plt.ylabel('Weight')
plt.xticks(rotation=90)
plt.grid(axis='y')
# 두 번째 주성분 (PC2)
plt.subplot(1, 2, 2)
components_df.loc['Principal Component 2'].plot(kind='bar')
plt.title('Contribution of Original Features to Principal Component 2')
plt.ylabel('Weight')
plt.xticks(rotation=90)
plt.grid(axis='y')
plt.tight_layout()
plt.show()7단계: PCA 주성분으로 K-Means 클러스터 시각화
# PCA 변환된 데이터를 데이터프레임으로
df_pca_clusters = pd.DataFrame(data=X_pca, columns=['Principal Component 1', 'Principal Component 2'])
df_pca_clusters['cluster'] = clusters
df_pca_clusters['actual_target'] = y
# PCA 주성분으로 K-Means 클러스터 시각화
plt.figure(figsize=(10, 6))
scatter_pca = plt.scatter(df_pca_clusters['Principal Component 1'],
df_pca_clusters['Principal Component 2'],
c=df_pca_clusters['cluster'],
cmap='viridis',
s=50,
alpha=0.8)
plt.xlabel('Principal Component 1 (Tumor Size/Invasiveness Factor)') # 해석된 이름 추가
plt.ylabel('Principal Component 2 (Tumor Texture/Smoothness Factor)') # 해석된 이름 추가
plt.title('K-Means Clusters on PCA Components (Breast Cancer Dataset)')
plt.colorbar(scatter_pca, label='Cluster Label')
plt.grid(True)
plt.show()
# 실제 진단 결과로 시각화 (비교)
plt.figure(figsize=(10, 6))
scatter_pca_actual = plt.scatter(df_pca_clusters['Principal Component 1'],
df_pca_clusters['Principal Component 2'],
c=df_pca_clusters['actual_target'],
cmap='viridis',
s=50,
alpha=0.8)
plt.xlabel('Principal Component 1 (Tumor Size/Invasiveness Factor)')
plt.ylabel('Principal Component 2 (Tumor Texture/Smoothness Factor)')
plt.title('Actual Diagnosis on PCA Components (Breast Cancer Dataset)')
plt.colorbar(scatter_pca_actual, label='Actual Diagnosis')
plt.grid(True)
plt.show()[코드2] PCA 결과 > K-means 클러스터링
워크플로우:
- 원본 데이터 (고차원)
- 데이터 표준화 (Standardization)
- PCA 적용 (차원 축소) → PCA 변환된 데이터 (저차원 주성분)
- **K-means 클러스터링 수행 (PCA 변환된 데이터 사용)
PCA 결과를 활용하면 좋은 점
- 차원의 저주(Curse of Dimensionality) 완화
- 노이즈 감소
- 계산 효율성 증가
- 시각화 용이성
1단계 데이터 로드, 표준화 및 PCA 변환
X_pca: 30차원의 원본 데이터가 2차원으로 압축된 데이터
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_breast_cancer
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.cluster import KMeans
# 유방암 데이터셋 로드
cancer = load_breast_cancer()
X = cancer.data # 30개의 특성 데이터
y = cancer.target # 실제 진단 결과 (0: 악성, 1: 양성)
feature_names = cancer.feature_names
print(f"원본 데이터셋의 차원 (샘플 수, 특성 수): {X.shape}")
# 데이터 표준화
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
print("데이터 표준화 완료.")
# PCA 적용 (2개의 주성분으로 축소)
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_scaled)
print(f"PCA 적용 후 데이터의 차원: {X_pca.shape}")
print(f"각 주성분이 설명하는 분산 비율: {pca.explained_variance_ratio_}")
print(f"누적 설명 분산 비율: {np.sum(pca.explained_variance_ratio_):.4f}")
# 주성분 해석 (이전 단계에서 수행했던 내용)
components_df = pd.DataFrame(pca.components_,
columns=feature_names,
index=['Principal Component 1', 'Principal Component 2'])
# print("\n주성분 벡터 (보기 쉬운 형태):\n", components_df) # 필요시 출력2단계: PCA 변환 데이터로 K-Means 클러스터링 수행
kmeans_pca.fit_predict(X_pca): PCA 변환된 2차원 데이터를 기반으로 클러스터링, 각 샘플이 속하는 클러스터 라벨(clusters_pca)이 생성
# PCA 변환된 데이터(X_pca)를 사용하여 K-Means 클러스터링 수행
# n_clusters=2 (악성/양성 두 그룹으로 분류되므로), random_state로 재현성 확보
kmeans_pca = KMeans(n_clusters=2, random_state=42, n_init=10)
clusters_pca = kmeans_pca.fit_predict(X_pca)
print(f"\nK-Means (PCA 데이터 기반) 클러스터링 결과 (처음 10개 샘플의 클러스터 라벨):\n {clusters_pca[:10]}")3단계: 클러스터링 결과 시각화 및 비교
좌측 그래프 (PCA 기반 K-Means 클러스터): K-means 클러스터가 매우 명확하게 두 그룹으로 분리(경계가 뚜렷, 오버랩X)
우측 그래프 (실제 진단 결과): 매우 유사하게 분리
# PCA 변환된 데이터를 데이터프레임으로
df_pca_clusters_new = pd.DataFrame(data=X_pca, columns=['Principal Component 1', 'Principal Component 2'])
df_pca_clusters_new['KMeans_Cluster'] = clusters_pca # PCA 기반 K-Means 클러스터 라벨
df_pca_clusters_new['Actual_Diagnosis'] = y # 실제 진단 결과
# PCA 주성분으로 K-Means 클러스터 결과 시각화
plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1) # 첫 번째 서브플롯: K-Means 클러스터 결과
scatter_kmeans = plt.scatter(df_pca_clusters_new['Principal Component 1'],
df_pca_clusters_new['Principal Component 2'],
c=df_pca_clusters_new['KMeans_Cluster'],
cmap='viridis', # 색상 맵 변경 가능 (e.g., 'RdBu', 'Paired')
s=50,
alpha=0.8)
plt.xlabel('Principal Component 1 (Tumor Size/Invasiveness Factor)')
plt.ylabel('Principal Component 2 (Tumor Texture/Smoothness Factor)')
plt.title('K-Means Clusters on PCA Components')
plt.colorbar(scatter_kmeans, label='Cluster Label')
plt.grid(True)
plt.subplot(1, 2, 2) # 두 번째 서브플롯: 실제 진단 결과
scatter_actual = plt.scatter(df_pca_clusters_new['Principal Component 1'],
df_pca_clusters_new['Principal Component 2'],
c=df_pca_clusters_new['Actual_Diagnosis'],
cmap='viridis', # K-Means와 동일한 색상 맵 사용
s=50,
alpha=0.8)
plt.xlabel('Principal Component 1 (Tumor Size/Invasiveness Factor)')
plt.ylabel('Principal Component 2 (Tumor Texture/Smoothness Factor)')
plt.title('Actual Diagnosis on PCA Components')
plt.colorbar(scatter_actual, label='Diagnosis (0: Malignant, 1: Benign)')
plt.grid(True)
plt.tight_layout()
plt.show()t-SNE이란?(t-Distributed Stochastic Neighbor Embedding)
고차원 데이터의 국소적 구조를 보존하면서 저차원으로 매핑하는 비선형 차원 축소 기법
각 데이터 사이 '거리'를 최대한 보존
(장점) 비선형 구조를 2D로 시각화, 경계 선명, 국소적 이웃 관계 잘 보존, 다양한 데이터 타입
(단점) 계산 비용 높음, 절대적 의미 해석 불가, 하이퍼파라미터에 민감, 실행할 때마다 다른 결과
[코드]
1단계 데이터 로드 및 표준화, K-means 클러스터링 진행
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_breast_cancer
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import KMeans
from sklearn.decomposition import PCA # PCA를 위해 추가
from sklearn.manifold import TSNE # t-SNE를 위해 추가
# 유방암 데이터셋 로드
cancer = load_breast_cancer()
X = cancer.data
y = cancer.target
feature_names = cancer.feature_names
# 데이터 표준화
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# K-Means 클러스터링 수행 (원본 데이터 기반)
kmeans = KMeans(n_clusters=2, random_state=42, n_init=10)
clusters = kmeans.fit_predict(X_scaled)2단계 PCA 및 t-SNE 적용
# PCA 적용 (2개의 주성분으로 축소)
pca = PCA(n_components=2, random_state=42) # random_state 추가로 재현성 확보
X_pca = pca.fit_transform(X_scaled)
print(f"PCA 적용 후 데이터의 차원: {X_pca.shape}")
print(f"PCA 누적 설명 분산 비율: {np.sum(pca.explained_variance_ratio_):.4f}")
# t-SNE 적용 (2개의 차원으로 축소)
tsne = TSNE(n_components=2, random_state=42, perplexity=30)
print("\nt-SNE 차원 축소 시작 (시간이 다소 소요될 수 있습니다)...")
X_tsne = tsne.fit_transform(X_scaled)
print("t-SNE 차원 축소 완료.")
print(f"t-SNE 적용 후 데이터의 차원: {X_tsne.shape}")3단계: 시각화를 통한 비교
# PCA 변환 데이터를 데이터프레임으로
df_pca = pd.DataFrame(data=X_pca, columns=['Principal Component 1', 'Principal Component 2'])
df_pca['KMeans_Cluster'] = clusters # K-Means 클러스터 라벨
# t-SNE 변환 데이터를 데이터프레임으로
df_tsne = pd.DataFrame(data=X_tsne, columns=['t-SNE Component 1', 't-SNE Component 2'])
df_tsne['KMeans_Cluster'] = clusters # K-Means 클러스터 라벨
# PCA와 t-SNE 결과를 나란히 비교 시각화
plt.figure(figsize=(16, 7)) # 전체 그림 크기 조정
# -------------------- PCA 결과 시각화 --------------------
plt.subplot(1, 2, 1) # 1행 2열 중 첫 번째 서브플롯
scatter_pca_compare = plt.scatter(df_pca['Principal Component 1'],
df_pca['Principal Component 2'],
c=df_pca['KMeans_Cluster'],
cmap='viridis',
s=50,
alpha=0.8)
plt.xlabel('Principal Component 1')
plt.ylabel('Principal Component 2')
plt.title('K-Means Clusters on PCA Components')
plt.colorbar(scatter_pca_compare, label='Cluster Label')
plt.grid(True)
# -------------------- t-SNE 결과 시각화 --------------------
plt.subplot(1, 2, 2) # 1행 2열 중 두 번째 서브플롯
scatter_tsne_compare = plt.scatter(df_tsne['t-SNE Component 1'],
df_tsne['t-SNE Component 2'],
c=df_tsne['KMeans_Cluster'],
cmap='viridis',
s=50,
alpha=0.8)
plt.xlabel('t-SNE Component 1')
plt.ylabel('t-SNE Component 2')
plt.title('K-Means Clusters on t-SNE Components')
plt.colorbar(scatter_tsne_compare, label='Cluster Label')
plt.grid(True)
plt.tight_layout() # 서브플롯 간 간격 자동 조정
plt.show()
# -------------------- 실제 진단 결과 비교 시각화 --------------------
plt.figure(figsize=(16, 7))
plt.subplot(1, 2, 1) # PCA 기반 실제 진단 결과
scatter_pca_actual_compare = plt.scatter(df_pca['Principal Component 1'],
df_pca['Principal Component 2'],
c=y, # 실제 진단 결과
cmap='viridis',
s=50,
alpha=0.8)
plt.xlabel('Principal Component 1')
plt.ylabel('Principal Component 2')
plt.title('Actual Diagnosis on PCA Components')
plt.colorbar(scatter_pca_actual_compare, label='Diagnosis (0: Malignant, 1: Benign)')
plt.grid(True)
plt.subplot(1, 2, 2) # t-SNE 기반 실제 진단 결과
scatter_tsne_actual_compare = plt.scatter(df_tsne['t-SNE Component 1'],
df_tsne['t-SNE Component 2'],
c=y, # 실제 진단 결과
cmap='viridis',
s=50,
alpha=0.8)
plt.xlabel('t-SNE Component 1')
plt.ylabel('t-SNE Component 2')
plt.title('Actual Diagnosis on t-SNE Components')
plt.colorbar(scatter_tsne_actual_compare, label='Diagnosis (0: Malignant, 1: Benign)')
plt.grid(True)
plt.tight_layout()
plt.show()4
3
'특강 > 머신러닝' 카테고리의 다른 글
| [머신러닝 주요기법] 3회차 (07.02)☆elbow, silhouette (2) | 2025.07.02 |
|---|---|
| [머신러닝 주요기법] 2회차 (07.01) (2) | 2025.07.01 |
| [머신러닝 주요기법] 1회차 (06.30) (1) | 2025.06.30 |
| [머신러닝] 4회차 앙상블, 부스팅(06.27) (2) | 2025.06.27 |
| [머신러닝] 3회차 회귀분석 (06.26) (0) | 2025.06.26 |