회귀분석이란?
종속변수(목표)와 독립변수(설명) 간의 관계 모델링 후 예측 및 통찰하는 통계적 기법
최적의 a,b 찾기
선형회귀란?
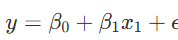
- y: 예측하려는 종속변수
- x1: 독립변수 (종속변수에 영향을 미치는 변수)
- β0: 절편 (모델의 시작점)
- β1: 기울기 (독립변수가 종속변수에 미치는 영향의 크기)
- ϵ: 오차 (모델의 예측값과 실제값 간의 차이)
# 라이브러리 불러오기
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
import matplotlib.pyplot as pltfrom sklearn.model_selection import train_test_split
# 데이터 준비
X = [[1], [2], [3], [4], [5]]
y = [2, 4, 6, 8, 10]
# 데이터 분리
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 선형 회귀 모델 생성 및 학습
from sklearn.linear_model import LinearRegression
model = LinearRegression()
model.fit(X_train, y_train)# 예측 및 평가
y_pred = model.predict(X_test)
print("MSE:", mean_squared_error(y_test, y_pred))
print("회귀 계수 (W):", model.coef_)
print("절편 (b):", model.intercept_)# 그래프 그리기
plt.scatter(X, y, color='blue', label='Actual data') # 실제 데이터
plt.plot(X, model.predict(X), color='red', label='Regression line') # 회귀선
plt.scatter(X_test, y_test, color='orange', label='Test data') # 테스트 데이터
plt.title("Linear Regression Visualization")
plt.xlabel("X")
plt.ylabel("y")
plt.legend()
plt.show()다중 선형회귀란?
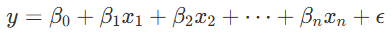
- x1,x2,…,xn: 여러 독립변수 (공부 시간, 수면 시간 등)
- y: 종속변수 (시험 점수)
#라이브러리 준비하기
import numpy as np
import pandas as pd
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split# 데이터 생성 독립 변수 (x1, x2)
X = np.array([[1, 2], [2, 3], [3, 5], [4, 6], [5, 8]])
y = np.array([3, 5, 7, 9, 11])
# 데이터 분리
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 모델 생성 및 학습
model = LinearRegression()
model.fit(X_train, y_train)# 결과 확인
print("회귀 계수 (W):", model.coef_)
print("절편 (b):", model.intercept_)
# 예측 및 평가
y_pred = model.predict(X_test)
print("예측 값:", y_pred)경사하강법이란?
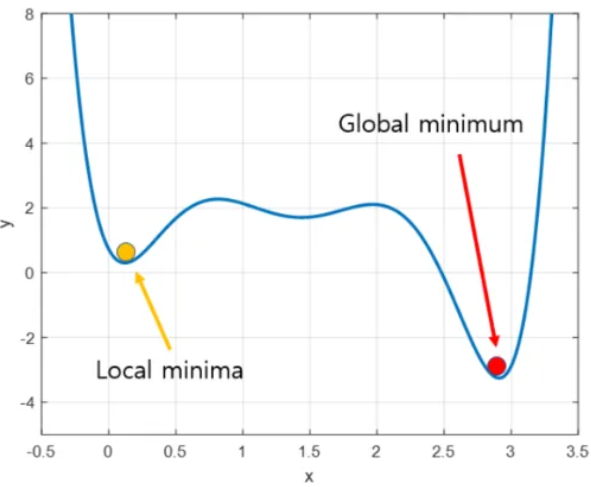
오차가 가장 작게 나오는 지점을 찾기 위해 가중치를 계속해서 업데이트 하는 방법
최적의 w,b 찾기
- 학습률(Learning Rate): 한번에 얼마나 큰 걸음을 내딛을지
- 경사(Gradient): 가장 가파른 내리막 계산 > 가중치 조절
- Local minima 문제
# 라이브러리 불러오기
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import SGDRegressor
from sklearn.model_selection import train_test_split# 데이터 생성
X = np.array([[1], [2], [3], [4], [5]])
y = np.array([2, 4, 6, 8, 10])
# 학습 데이터와 테스트 데이터 분리
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 모델 학습 (SGDRegressor 사용)
# max_iter: 최대 반복횟수
# tol: 수렴 조건
model = SGDRegressor(max_iter=1000, tol=1e-3) # max_iter: 최대 반복 횟수, tol: 수렴 조건
model.fit(X_train, y_train)# 결과 확인
print("회귀 계수 (W):", model.coef_)
print("절편 (b):", model.intercept_)
# 예측
y_pred = model.predict(X_test)
print("예측 값:", y_pred)# 그래프 그리기
plt.scatter(X, y, color='blue', label='실제 값')
plt.plot(X, model.predict(X), color='red', label='회귀 직선')
plt.xlabel('X')
plt.ylabel('y')
plt.legend()
plt.title('SGDRegressor를 통한 선형 회귀')
plt.show()모델 성능평가
평균 제곱 오차(MSE)
- 실제 값과 예측 값간의 차이를 제곱하여 평균 구하기
- 예측이 정확할수록 0에 가까움
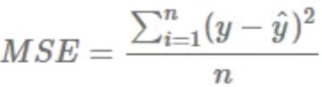
from sklearn.metrics import mean_squared_error
# 예시 데이터 (실제 값과 예측 값)
y_true = [3, -0.5, 2, 7]
y_pred = [2.5, 0.0, 2, 8]
# MSE 계산
mse = mean_squared_error(y_true, y_pred)
# 결과 출력
print("MSE:", mse)평균 제곱근 오차(RMSE)
MSE의 제곱근

from sklearn.metrics import mean_squared_error
import numpy as np
# 예시 데이터 (실제 값과 예측 값)
y_true = [3, -0.5, 2, 7]
y_pred = [2.5, 0.0, 2, 8]
# MSE 계산
mse = mean_squared_error(y_true, y_pred)
# RMSE 계산 (MSE의 제곱근)
rmse = np.sqrt(mse)
# 결과 출력
print("RMSE:", rmse)결정 계수(R2, R-squared)
- 실제 값의 변동성을 얼마나 잘 설명하는지
- 모델이 잘 작동하면 1에 가까움
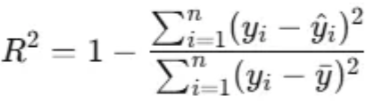
from sklearn.metrics import r2_score
# 예시 데이터 (실제 값과 예측 값)
y_true = [3, -0.5, 2, 7]
y_pred = [2.5, 0.0, 2, 8]
# R² 스코어 계산
r2 = r2_score(y_true, y_pred)
# 결과 출력
print("R² 스코어:", r2)릿지 회귀 (Ridge) L2 정규화
가중치(회귀 계수)크기가 너무 커지지 않도록 벌점(penalty)을 추가하는 방법
람다(λ) = 싸이킷런(alpha) ⇒ 벌점의 강도
- 작은 λ : 모델이 복잡해짐
- 큰 λ : 모델이 단순해짐




- 과적합 방지
- 모델 복잡도 감소
>> 모델의 안정성, 특성 간 상관 관계 처리
from sklearn.linear_model import Ridge
# 모델 학습
ridge_reg = Ridge(alpha=1.0) #alpha는 벌점을 얼마나 강하게 적용할지 결정하는 값
ridge_reg.fit(X, y)
# 예측
y_pred = ridge_reg.predict(X)라쏘회귀 (Lasso) L1 정규화
가중치를 0으로 만들도록 유도
람다(λ) = 코드(alpha) ⇒ 벌점의 강도
- 작은 λ : 모델이 복잡해짐
- 큰 λ : 모델이 단순해짐
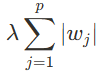

- 과적합 방지
- 특성 선택
- 모델 간소화
from sklearn.linear_model import Lasso
# 모델 학습
lasso_reg = Lasso(alpha=0.1)
lasso_reg.fit(X, y)
# 예측
y_pred = lasso_reg.predict(X)엘라스틱 회귀 (Elasticnet)
릿지 회귀(L2 정규화)와 라쏘 회귀( L1 정규화)를 결합한 선형 회귀 기법 이 기법은 두 정규화 기법의 장점을 모두 활용하는 모델
- α = 0 이면, 릿지
- α = 1 이면, 라쏘
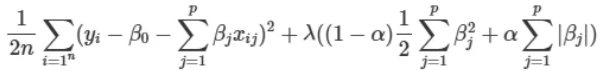
from sklearn.linear_model import ElasticNet
# 모델 학습
elastic_net_reg = ElasticNet(alpha=0.1, l1_ratio=0.5) # l1_ratio=0.5: L1과 L2의 균형
#l1_ratio=0.3이라면? L1 정규화와 L2 정규화를 3:7 비율
elastic_net_reg.fit(X, y)
# 예측
y_pred = elastic_net_reg.predict(X)
'특강 > 머신러닝' 카테고리의 다른 글
| [머신러닝 주요기법] 2회차 (07.01) (2) | 2025.07.01 |
|---|---|
| [머신러닝 주요기법] 1회차 (06.30) (1) | 2025.06.30 |
| [머신러닝] 4회차 앙상블, 부스팅(06.27) (2) | 2025.06.27 |
| [머신러닝] 2회차 머신러닝 핵심기술(06.25) (2) | 2025.06.25 |
| [머신러닝] 1회차 (06.24) (3) | 2025.06.24 |