인코딩(Encoding): 범주형 데이터를 숫자로 변환하는 과정
범주형 데이터란?
- 숫자같은 연속 값이 아니라, 의미 있는 그룹 값
- 머신러닝은 숫자만 입력 가능
- 문자열 그대로 학습 불가
1. OneHot Encoding
- 순서 없는 범주형 변수
- 범주의 개수가 적당 할 때
- 각 범주를 새로운 열로 만들어 0/1 표시
import pandas as pd
# 1. 샘플 데이터프레임 생성
df = pd.DataFrame({
'name': ['Alice', 'Bob', 'Charlie', 'David'],
'blood_type': ['A', 'B', 'O', 'A']
})
# 2. One-Hot Encoding 적용
df_encoded = pd.get_dummies(df, columns=['blood_type'])
print("\nOne-Hot Encoding 결과:")
print(df_encoded)

2. Label Encoder
- 순서 있는 범주형 변수
- 범주의 개수가 많을 때
- 각 범주에 대한 고유한 정수값 할당
import pandas as pd
from sklearn.preprocessing import LabelEncoder
# 예시 데이터
df = pd.DataFrame({
'name': ['Alice', 'Bob', 'Charlie', 'David'],
'satisfaction': ['만족', '보통', '불만', '만족']
})
# Label Encoding
le = LabelEncoder()
df['satisfaction_encoded'] = le.fit_transform(df['satisfaction'])
print("\nLabel Encoding 결과:")
print(df)
스케일링(Scaling): 수치형 데이터의 단위를 맞추는 과정
- 입력 변수들의 크기 차이에 민감
- 편향되게 학습할 가능성
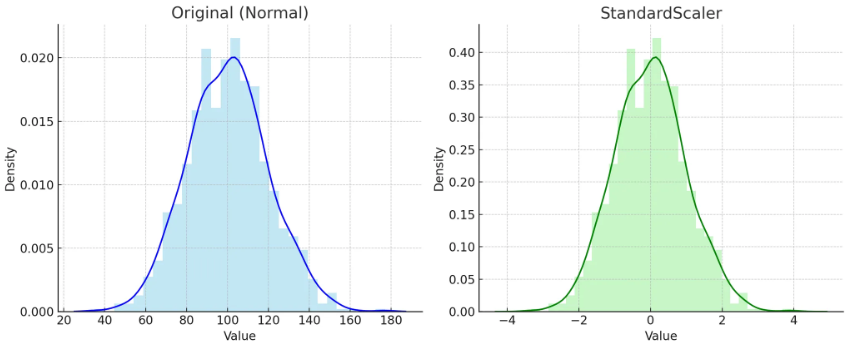
1. 표준화(Standard Scaler)
- 평균 0, 표준편차 1로 변환
- 정규분포에 가깝거나 대칭일 때
- 데이터의 모양(분포 곡선) 유지하며 중심 0, 크기 1로 변경
from sklearn.preprocessing import StandardScaler
# 예시 데이터 (5개의 샘플, 2개의 특성)
X_train = [[1, 2], [3, 4], [5, 6], [7, 8], [9, 10]]
# StandardScaler 초기화
scaler = StandardScaler()
# 데이터 표준화
X_train_scaled = scaler.fit_transform(X_train)
print(X_train_scaled)
#[[-1.41421356 -1.41421356], [-0.70710678 -0.70710678], [ 0 0 ], [ 0.70710678 0.70710678], [ 1.41421356 1.41421356]]2. 정규화(MinMax Scaler)
- 각 값을 0 ~ 1 사이로 변환
- 값의 범위를 일정한 크기로 맞춰야 할 때
- 비정규형일 때

from sklearn.preprocessing import MinMaxScaler
# 예시 데이터 (5개의 샘플, 2개의 특성)
X_train = [[1, 2], [3, 4], [5, 6], [7, 8], [9, 10]]
# MinMaxScaler 초기화
scaler = MinMaxScaler()
# 데이터 정규화
X_train_scaled = scaler.fit_transform(X_train)
print(X_train_scaled)
#[[0. 0. ], [0.25 0.25], [0.5 0.5 ], [0.75 0.75], [1. 1. ]]다중공선성 제거(Multicollinearity)
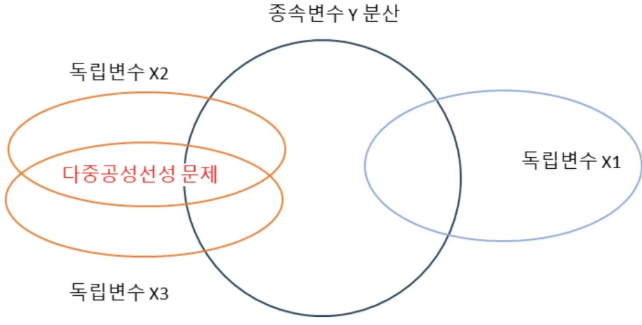
다중공선성이란?
- 독립 변수들 간에 상관관계가 강한 경우
- (선형 모델)계수 추정이 불안정, 해석 어려움
- (비선형 모델 ex.랜덤포레스트)과적합, 모델 해석 왜곡, 훈련 데이터 효율성 저하
과적합이란?
- 학습 데이터에 지나치게 최적화되어, 새로운 데이터에 대한 예측 성능이 저하되는 현상
- (이유)모델이 너무 복잡할 때, 훈련 데이터가 부족할 때, 노이즈가 많은 데이터
- (방지)모델의 복잡도 줄이기, 더 많은 훈련 데이터, 정규화, 교차 검증
처리 해야하는 경우: 모델링 목적 = '해석'
처리하지 않아도 되는 경우: 모델링 목적 = '예측'
1. VIF기반 변수제거
VIF(Variance Inflation Factor) 값이 10이상 제거
- 모든 변수 VIF 계산
- VIF 값이 가장 높은 변수 제거 후 VIF 계산
- VIF 값이 10이하까지 반복
from statsmodels.stats.outliers_influence import variance_inflation_factor
def calculate_vif(X):
vif_data = pd.DataFrame()
vif_data["Variable"] = X.columns
vif_data["VIF"] = [variance_inflation_factor(X.values, i)
for i in range(X.shape[1])]
return vif_data.sort_values('VIF', ascending=False)2. 높은 상관관계를 가진 변수제거
상관계수 0.9이상인 변수 쌍 중 하나 제거
- 피어슨 상관행렬 계산
- 상관계수가 0.9이상인 변수 쌍 찾기
- 도메인 지식/모델 성능 고려 후 제거
# 상관계수 행렬 계산
# df_numeric: 임의의 데이터
corr_matrix = df_numeric.corr().abs()
# 상관관계가 높은 변수 찾기
threshold = 0.9
high_corr_vars = set()
for i in range(len(corr_matrix.columns)):
for j in range(i):
if corr_matrix.iloc[i, j] > threshold:
colname = corr_matrix.columns[i]
high_corr_vars.add(colname)
# 상관계수가 높은 변수 제거
df_corr_reduced = df_numeric.drop(columns=high_corr_vars)
print("제거된 변수들:", high_corr_vars)3. PCA 분석
다중공선성 높은 변수를 제거하기 않고, 새로운축으로 변환하여 차원을 줄이는 방법
주요 정보 유지 후 변수 축소 >> 변수 학습에 효율적
but. 해석력 떨어질 수 있음, 변수 중요도를 직접 해석하기 어려
- 주성분 개수(n) 결정
- PCA 적용하여 새로운 변수로 변환
- 변환된 변수를 모델에 사용
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
# 데이터 표준화(데이터의 크기가 PCA에 영향을 미치므로 StandardScaler() 적용)
# df_numeric: 임의의 데이터
scaler = StandardScaler()
df_scaled = scaler.fit_transform(df_numeric)
# PCA 적용
pca = PCA(n_components=0.95) # 설명된 분산 95% 유지
df_pca = pca.fit_transform(df_scaled)
print(f"PCA 적용 후 차원 수: {df_pca.shape[1]}")데이터 분할(Split)
모델 훈련 및 평가를 위해 훈련데이터(Train)과 테스트데이터(Test)로 나뉨 >> 과적합 방지
훈련데이터(Train): 모델 학습에 사용
테스트데이터(Test): 모델이 처음보는 데이터, 일반화 성능 평가
(train : test = 7:3, 8:2, 6:4)
import pandas as pd
from sklearn.model_selection import train_test_split
# 예시 데이터 생성
data = {
'feature1': range(100),
'feature2': range(100, 200),
'label': [0]*80 + [1]*20 # 불균형 데이터
}
df = pd.DataFrame(data)
# X(입력), y(출력) 분리
X = df[['feature1', 'feature2']]
y = df['label']
# 데이터 분할 (stratify로 클래스 비율 유지)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42)
# 결과 확인
print("훈련 데이터 크기:", X_train.shape) #훈련 데이터 크기: (70, 2)
print("테스트 데이터 크기:", X_test.shape) #테스트 데이터 크기: (30, 2)샘플링(Sampling)
데이터 불균형이란?
정상 범주의 관측치 수와 이상 범주의 관측치 수가 현저히 차이나는 데이터
일반적으로 이상을 정확히 분류하는 것이 중요 >> 이상 데이터가 target값이 되는 경우가 많음
QA/QC 관점
- 불균형 데이터의 위험: 정확도 함정, 결함 탐지 실패
- QA/QC 목표: 데이터 균형 유지
- QA 해결방안: 데이터 수집 전략 강화, 모델 검증 강화
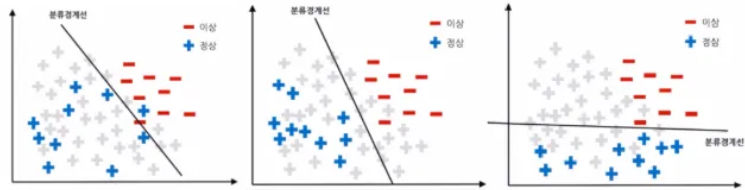
1. 언더 샘플링(replace = False)
다수 범주의 데이터를 소수 범주의 데이터 수에 맞게 줄이는 방식
Random Sampling: 다수 범주에서 무작위로 샘플링
import numpy as np
import pandas as pd
from sklearn.utils import resample
# 예제 데이터셋 생성
data = {'feature1': np.random.randn(1000), # 랜덤 피처 데이터
'feature2': np.random.randn(1000),
'class': [0] * 900 + [1] * 100} # 클래스 불균형 (0: 900개, 1: 100개)
df = pd.DataFrame(data)
# 클래스 분리
df_majority = df[df['class'] == 0] # 다수 클래스 (0)
df_minority = df[df['class'] == 1] # 소수 클래스 (1)
# 랜덤 언더샘플링
df_majority_downsampled = resample(df_majority,
replace=False, # 복제하지 않음
n_samples=len(df_minority), # 소수 클래스 크기와 동일
random_state=42) # 재현성을 위해
# 언더샘플링 데이터 병합
df_balanced = pd.concat([df_majority_downsampled, df_minority])
print("언더샘플링 전 데이터 분포:")
print(df['class'].value_counts())
print("\n언더샘플링 후 데이터 분포:")
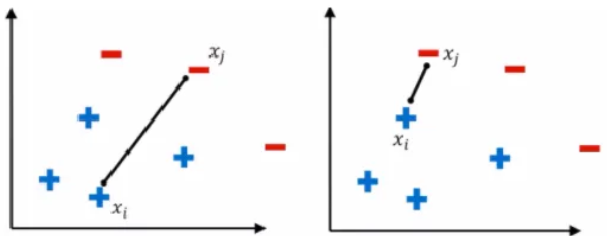
print(df_balanced['class'].value_counts())Tomek Links: 두데이터의 거리가 짧을 때만 선택하여 샘플링(경계선을 지우는 방식)


from imblearn.under_sampling import TomekLinks
import numpy as np
import pandas as pd
# 예제 데이터 생성
np.random.seed(42)
X = np.vstack((np.random.normal(0, 1, (100, 2)), np.random.normal(3, 1, (10, 2)))) # 피처 데이터
y = np.array([0] * 100 + [1] * 10) # 클래스 라벨 (불균형)
# Tomek Link 적용
tomek = TomekLinks(sampling_strategy='auto') # 다수 클래스 데이터만 제거
X_resampled, y_resampled = tomek.fit_resample(X, y)
# 결과 출력
print("Tomek Link 적용 전 데이터 크기:", X.shape)
print("Tomek Link 적용 후 데이터 크기:", X_resampled.shape)
print("원래 클래스 분포:", pd.Series(y).value_counts())
print("Tomek Link 적용 후 클래스 분포:", pd.Series(y_resampled).value_counts())2. 오버 샘플링(replace = True)
소수 범주의 데이터를 다수 범주의 데이터 수에 맞게 늘리는 샘플링 방식
Resampling: 소수 클래스 데이터 단순 복제

import numpy as np
import pandas as pd
from sklearn.utils import resample
# 예제 데이터셋 생성
data = {'feature1': np.random.randn(1000), # 랜덤 피처 데이터
'feature2': np.random.randn(1000),
'class': [0] * 900 + [1] * 100} # 클래스 불균형 (0: 900개, 1: 100개)
df = pd.DataFrame(data)
# 클래스 분리
df_majority = df[df['class'] == 0] # 다수 클래스 (0)
df_minority = df[df['class'] == 1] # 소수 클래스 (1)
# 랜덤 언더샘플링
df_majority_downsampled = resample(df_majority,
replace=False, # 복제하지 않음
n_samples=len(df_minority), # 소수 클래스 크기와 동일
random_state=42) # 재현성을 위해
# 언더샘플링 데이터 병합
df_balanced = pd.concat([df_majority_downsampled, df_minority])
print("언더샘플링 전 데이터 분포:")
print(df['class'].value_counts())
print("\n언더샘플링 후 데이터 분포:")
print(df_balanced['class'].value_counts())SMOTE: 소수 범주에서 가상의 데이터를 선형보간하여 생성
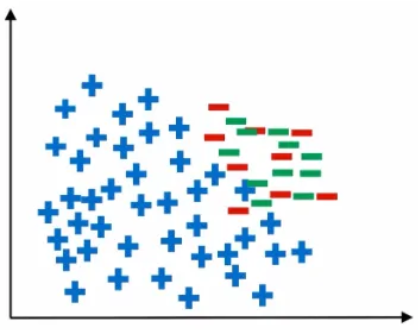
from imblearn.over_sampling import SMOTE
import numpy as np
import pandas as pd
# 데이터 생성 (불균형 데이터셋)
X = np.array([[1, 2], [2, 3], [3, 4], [4, 5], [10, 10], [20, 20]]) # 특징 데이터
y = np.array([0, 0, 0, 1, 1, 1]) # 클래스 (불균형 데이터)
print("SMOTE 적용 전 클래스 분포:")
print(pd.Series(y).value_counts())
# SMOTE 초기화 (k_neighbors=2)
smote = SMOTE(k_neighbors=2, random_state=42)
# 데이터 오버샘플링
X_resampled, y_resampled = smote.fit_resample(X, y)
print("\nSMOTE 적용 후 클래스 분포:")
print(pd.Series(y_resampled).value_counts())
print("\nSMOTE로 생성된 데이터:")
print(X_resampled)Borderline SMOTE: 경계 근처 데이터만 사용

- Safe 관측치:대부분의 이웃이 소수 클래스 → 학습에 문제가 없는 안전한 데이터
- Danger 관측치:다수 클래스 데이터와 섞여 있어 경계에 위치한 위험한 데이터
- Noise 관측치:거의 모든 이웃이 다수 클래스 → 소음 데이터
'특강 > 머신러닝' 카테고리의 다른 글
| [머신러닝 주요기법] 2회차 (07.01) (2) | 2025.07.01 |
|---|---|
| [머신러닝 주요기법] 1회차 (06.30) (1) | 2025.06.30 |
| [머신러닝] 4회차 앙상블, 부스팅(06.27) (2) | 2025.06.27 |
| [머신러닝] 3회차 회귀분석 (06.26) (0) | 2025.06.26 |
| [머신러닝] 1회차 (06.24) (3) | 2025.06.24 |