머신러닝 vs 딥러닝

공통점: 데이터로부터 가중치를 학습하여 패턴을 인식하고 결정을 내리는 알고리즘 개발과 관련된 인공지능(AI)의 하위 분야
차이점
- 머신러닝: 데이터 안의 통계적 관계를 찾아내 예측 및 분류
- 딥러닝: 머신러닝의 한 분야로 신경세포 구조를 모방한 인공 신경망을 사용(이미지, 자연어 처리)
[개념]
경사 하강법(Gradient Descent)
- 모델의 손실 함수를 최소화하기 위해 모델의 가중치를 반복적으로 조정하는 최적화 알고리즘
- 최소화 값: 목적 함수, 손실 함수 > MSE(에러) 도출
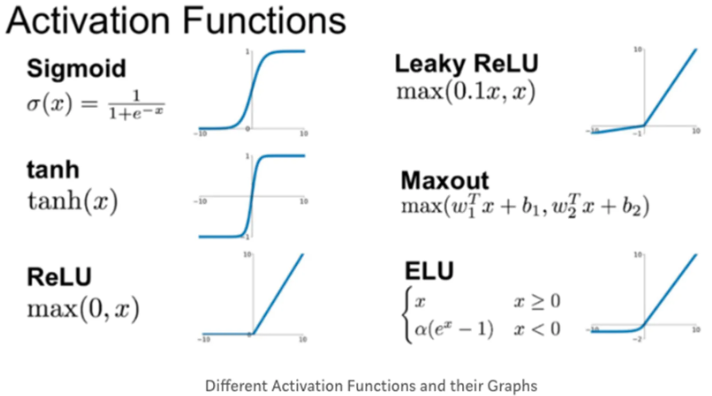
활성화 함수: 비선형적분류를 만들기 위함
레이어 등장
- 순전파(Propagation) : 입력 데이터가 신경망의 각 층을 통과하면서 최종 출력까지 생성되는 과정
- 역전파(Backpropagation) : 신경망의 오류를 역방향으로 전파하여 각 층의 가중치를 조절하는 과정

1. Input Layer: 주어진 데이터가 벡터(Vector)의 형태로 입력
2. Hidden Layer: Input Layer와 Output Layer를 매개하는 레이어로 이를 통해 비선형 문제를 해결 가능
3. Output Layer: 최종 목표
- Activation function(활성화 함수): 인공신경망의 비선형성을 추가하며 기울기 소실 문제 해결함
딥러닝의 반복

epoch: 전체 데이터가 신경망을 통과하는 한 번의 사이클
- 1000 epoch: 데이터 전체를 1000번 학습
batch: 전체 훈련 데이터 셋을 일정한 크기의 소 그룹으로 나눈 것
iteration: 전체 훈련 데이터 셋을 여러 개(=batch)로 나누었을 때 배치가 학습되는 횟수
딥러닝 코드(Tensorflow 패키지 이해)
tensorflow.keras.model.Sequential
- model.add: 모델에 대한 새로운 층을 추가함
- unit
- model.compile: 모델 구조를 컴파일하며 학습 과정을 설정
- optimizer : 최적화 방법, Gradient Descent 종류 선택
- loss : 학습 중 손실 함수 설정
- 회귀: mean_squared_error(회귀)
- 분류: categorical_crossentropy
- metrics : 평가척도
- mse: Mean Squared Error
- acc : 정확도
- f1_score: f1 score
- model.fit: 모델을 훈련 시키는 과정
- epochs: 전체 훈련 데이터 셋에 대해 학습을 반복하는 횟수
- model.summary(): 모델의 구조를 요약하여 출력
tensorflow.keras.model.Dense: 완전 연결된 층
- unit: 층에 있는 유닛의 수. 출력에 대한 차원 개수
- input_shape:1번째 층에만 필요하면 입력데이터의 형태를 지정
model.evaluate: 테스트 데이터를 사용하여 평가
model.predict: 새로운 데이터에 대해서 예측 수행
[실습]
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
import numpy as np
from sklearn.preprocessing import StandardScaler
weights = np.array([87,81,82,92,90,61,86,66,69,69])
heights = np.array([187,174,179,192,188,160,179,168,168,174])
#Sequential 모델 초기화
model = Sequential()
#단일을 추가하기
dense_layser = Dense(units = 1, input_shape=[1])
model.add(dense_layser)
model.compile(optimizer='adam', loss='mean_squared_error')
model.summary()
#학습시키기(loss 줄어듬)
model.fit(weights, heights, epochs=100)
#히든 레이어 만들기
model2 = Sequential()
model2.add(Dense(units=64, activation='relu', input_shape=[1]))
model2.add(Dense(units=64, activation='relu'))
model2.add(Dense(units=1))
model2.compile(optimizer='adam', loss='mean_squared_error')
model2.summary()
#학습시키기
model2.fit(weights, heights, epochs=100)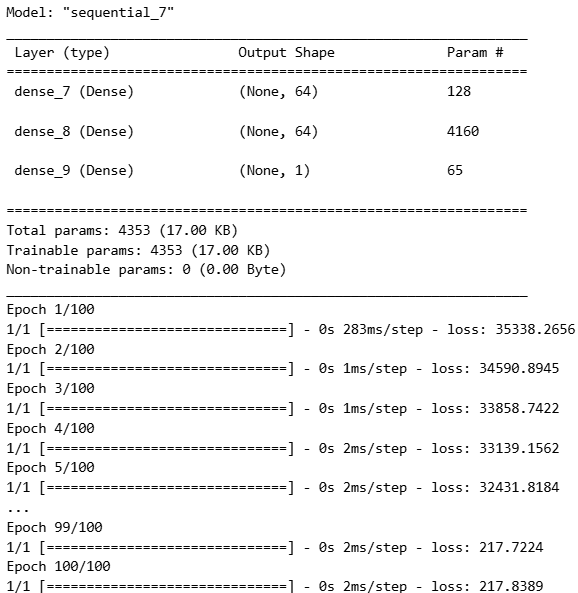
활용 예시
1. 자연어 처리: 인간의 언어를 데이터화 하는 것

+ 최신 자연어 처리(LLM)
ex. GPT-4(OpenAI), PaLM2(Google), LlaMA(Meta)
2. 이미지 처리: 3차원 데이터를 모델에 학습
+ 최신 이미지 처리
ex. mutimodal (텍스트, 이미지, 음성 등 다양한 유형의 데이터를 함계 사용)
'강의자료 > 머신러닝의 이해와 라이브러리 활용' 카테고리의 다른 글
| 요약☆ (0) | 2025.07.02 |
|---|---|
| 6강. 비지도학습 (07.02) (0) | 2025.07.02 |
| 5강. 회귀, 분류 모델링 심화 및 코드(07.01) ☆☆ (0) | 2025.07.02 |
| 4강. 데이터 분석 프로세스(06.30, 07.01) (2) | 2025.07.01 |
| 3강. 로지스틱회귀(범주/카테고리 분류)(06.26,27) (1) | 2025.06.30 |