로지스틱회귀란?
- 범주형 데이터 분류 분석
- 선형회귀(숫자)와 반대 개념

이론
X가 연속형 함수일 때, 범주형 Y에서 선형함수의 한계 >> S자 형태의 함수 적용 후 설명
오즈비에 log를 붙여 값 낮추기
해석: XX값이 w_1만큼 증가하면 오즈비는 (e^w1)만큼 증가한다.
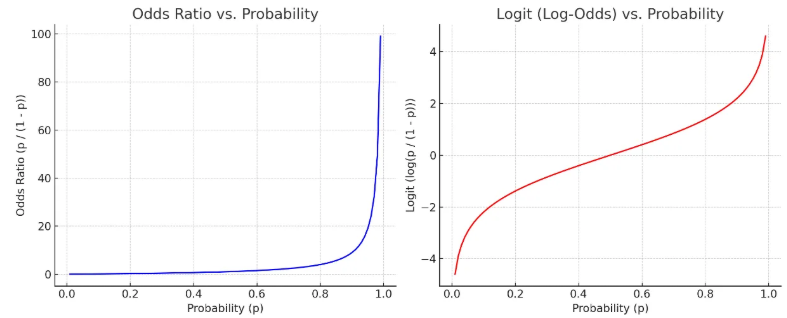

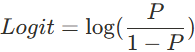
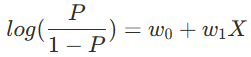
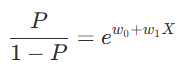
ex. 타이타닉
import pandas as pd
import seaborn as sns
titanic_df = pd.read_csv('C:/Users/2552y/OneDrive/바탕 화면/내일배움캠프/강의 자료/titanic/train.csv', encoding='utf-8')
titanic_df.head(3)
가설1: 비상상황 특성상 여성을 배려해서 여성이 남성보다 생존율이 높을 것이다.
- pivot table 만들어 확인
pd.pivot_table(titanic_df, index = 'Sex', columns = 'Survived', aggfunc = 'size')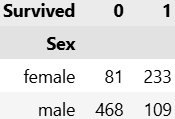
- 그래프 통해서 확인
sns.countplot(titanic_df, x = 'Sex', hue = 'Survived')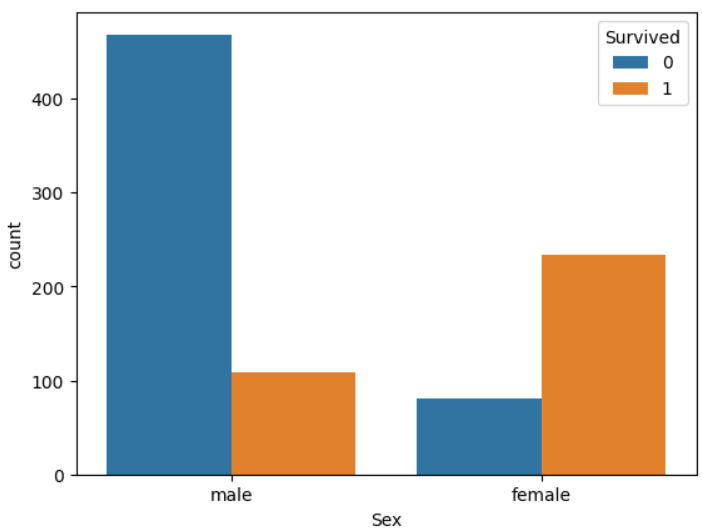
분류 평가 지표
1. 정확도와 F1-Score
혼동행렬

- TP: 실제로 양성(암 환자)이면서 양성(암 환자) 올바르게 분류된 수
- FP: 실제로 음성(정상인)이지만 양성(암 환자)로 잘못 분류된 수
- FN: 실제로 양성(암 환자)이지만 음성(정상인)로 잘못 분류된 수
- TN: 실제로 음성(정상인)이면서 음성(정상인)로 올바르게 분류된 수
- 정밀도(Precision)

- 재현율(Recall)

- F1-Score

- 정확도(Accuracy)

로지스틱회귀 실습(타이타닉)
자주쓰는 함수
sklearn.linear_model.LogisticRegression : 로지스틱회귀 모델 클래스
- 속성
- classes_: 클래스(Y)의 종류
- n_features_in_ : 들어간 독립변수(X) 개수
- feature_names_in_: 들어간 독립변수(X)의 이름
- coef_: 가중치
- intercept_: 바이어스
- 메소드
- fit: 데이터 학습
- predict: 데이터 예측
- predict_proba: 데이터가 Y = 1일 확률을 예측
sklearn.metrics.accuracy: 정확도
sklearn.metrics.f1_socre: f1_score
단일회귀
#Y(Survived)
#X(수치형): Fare
[훈련하기]
1. 라이브러리 설치 및 적용
import numpy as np
import matplotlib.pyplot as plt
import sklearn
import pandas as pd
import seaborn as sns2. 변수 지정
X_1 = titanic_df[['Fare']]
y_true = titanic_df[['Survived']]3. 산점도 확인하기
sns.scatterplot(titanic_df, x = 'Fare', y = 'Survived')
4. 머신러닝 베이스 생성 및 학습
from sklearn.linear_model import LogisticRegression
model_lor = LogisticRegression()
model_lor.fit(X_1, y_true)
5. 모델 넣고 확인하기
def get_att(X):
#X모델을 넣기
print('클래스 종류', X.classes_)
print('독립변수 개수', X.n_features_in_)
print('들어간 독립변수(X)의 이름', X.feature_names_in_)
print('가중치(회귀계수)', X.coef_)
print('바이어스(절편)', X.intercept_)
get_att(model_lor)
#클래스 종류 [0 1]
#독립변수 개수 1
#들어간 독립변수(X)의 이름 ['Fare']
#가중치(회귀계수) [[0.01519617]]
#바이어스(절편) [-0.94129222][평가하기]
1. 정확도 및 f1 score 모델 넣기
from sklearn.metrics import accuracy_score, f1_score
def get_metrics(true, pred):
print('정확도:', accuracy_score(true, pred))
print('F1 score:', f1_score(true, pred))2. 예측값 보기(권장X)(생략)
model_lor.predict(X_1)
3. 전체 예측값 확인하기
y_pred_1 = model_lor.predict(X_1)
get_metrics(y_true, y_pred_1)
#정확도: 0.6655443322109988
#F1 score: 0.354978354978355다중회귀
#Y(Survived)
#X(수치형): Fare
#X(범주형): Plcass, Sex
1. Sex 수치형으로 바꾸기(인코딩)
def get_sex(X):
if X == 'female':
return 0
else:
return 1
titanic_df['Sex_en'] = titanic_df['Sex'].apply(get_sex)2. 변수 지정
X_2 = titanic_df[['Fare', 'Pclass', 'Sex_en']]
y_true_2 = titanic_df[['Survived']]3. 모델 학습
model_lor_2 = LogisticRegression()
model_lor_2.fit(X_2, y_true_2)
4. 모델 확인하기
get_att(model_lor_2)
#클래스 종류 [0 1]
#독립변수 개수 3
#들어간 독립변수(X)의 이름 ['Fare' 'Pclass' 'Sex_en']
#가중치(회귀계수) [[ 1.64019087e-03 -8.88331324e-01 -2.53993425e+00]]
#바이어스(절편) [3.02004403]5. 예측값 넣고 확인하기
y_pred_2 = model_lor_2.predict(X_2)
get_metrics(y_true_2, y_pred_2)
#정확도: 0.7867564534231201
#F1 score: 0.71212121212121226. 특정 상황 넣어보기
# 각 데이터별 Y=1인 확률 뽑아내기(생존할 확률)
model_lor_2.predict_proba(X_2)비교하기
#단일회귀
get_metrics(y_true, y_pred_1)
#정확도: 0.6655443322109988
#F1 score: 0.354978354978355
#다중회귀
get_metrics(y_true_2, y_pred_2)
#정확도: 0.7867564534231201
#F1 score: 0.7121212121212122
'강의자료 > 머신러닝의 이해와 라이브러리 활용' 카테고리의 다른 글
| 6강. 비지도학습 (07.02) (0) | 2025.07.02 |
|---|---|
| 5강. 회귀, 분류 모델링 심화 및 코드(07.01) ☆☆ (0) | 2025.07.02 |
| 4강. 데이터 분석 프로세스(06.30, 07.01) (2) | 2025.07.01 |
| 2강. 회귀분석(선형회귀 정의 및 단순선형회귀 실습)(06.23,06.24) (0) | 2025.06.24 |
| 1강. 머신러닝 개념(06.18) (2) | 2025.06.19 |