선형회귀란?
주변의 점들이 직선(선형)으로 돌아가려하는 것(회귀)처럼 보임.
- 선형성
- 등분산성
- 정규성
- 독립성
- 장점: 직관적, X-Y관계 빠르게 정량화
- 단점: X-y간 선형성 가정 필요, 이상치에 민감, 인코딩시 정보 손실
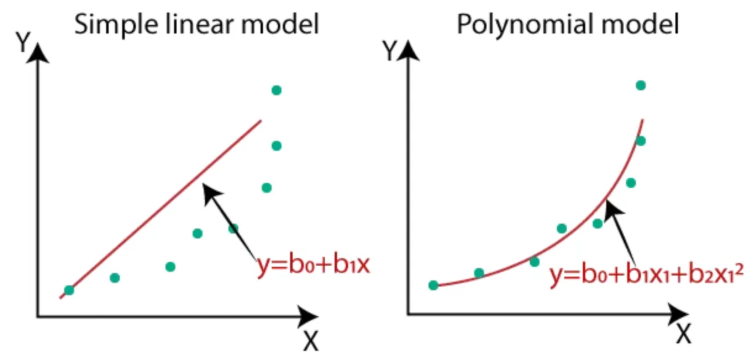
- Y: 종속, 결과 변수
- X: 독립, 원인 변수
- Y = B0 + B1X + e
- B0: 편향(절편)
- B1: 회귀 계수(기울기), 가중치(예측 가능)
- e: 오차(모델이 설명하지 못하는 Y의 변동성)

회귀분석 평가지표(Mean Squared Erorr = MSE)
에러(e) = 실제 데이터 - 예측 데이터

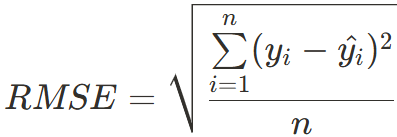

함수 정의 확인
1. 인터넷 있을때: sklearn linearregression 검색해서 들어가기
2. 인터넷 없을때: 쥬피터 노트북
help(sklearn.linear_model.LinearRegression)선형회귀만의 평가 지표(R square)



실습
[훈련하기]
1. 라이브러리 설치 및 적용
#실행 전 터미널에 pip install scikit-learn하기
import numpy as np
import matplotlib.pyplot as plt
import sklearn
import pandas as pd
import seaborn as sns2. 임의의 데이터 생성
weights = [87, 81, 82, 92, 90, 61, 86, 66, 69, 69]
heights = [187, 174, 179, 192, 188, 160, 179, 168, 168, 174]
body_df = pd.DataFrame({'weights': weights, 'heights': heights})
body_df.head(3)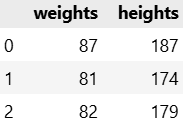
3. 선형그래프인지 확인(산점도)
sns.scatterplot(data=body_df, x='weights', y='heights')
plt.title('몸무게와 키의 산점도')
plt.xlabel('몸무게 (kg)')
plt.ylabel('키 (cm)')
4. 머신러닝 베이스 생성
from sklearn.linear_model import LinearRegression
model_lr = LinearRegression()
type(model_lr)
#X대문자, y소문자
#DF[]:대괄호 1개 = DF 컬럼
#DF[[]]:대괄호 2개 = DF (학습시킬때 차원 문제 방지)
X = body_df[['weights']]
y = body_df[['heights']]4. 머신러닝 훈련(학습)
model_lr.fit(X, y)
5. 확인해보기
#가중치(w1)=기울기
model_lr.coef_
#편향(bias, w0)=선형회귀식
model_lr.intercept_
print('y = {}x + {}'.format(w1.round(2), w0.round(2))) #round: 소수점 자리수
# y = 0.86X + 109.37
결론: y는 X에 0.86을 곱한뒤 109.37을 더하면된다.
[평가 전 해야할 일]
1. 컬럼 추가(예측값, 에러값, 양수만들기 위해 제곱)
#예측값
body_df['pred'] = body_df['weights'] * w1 + w0
#에러값
body_df['error'] = body_df['heights'] - body_df['pred']
#제곱값
body_df['error^2'] =body_df['error']*body_df['error']
#확인하기
body_df.head(3)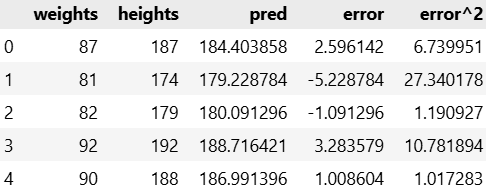
2. MSE 구하기(편차^2/데이터 수)
body_df['error^2'].sum()/len(body_df)[평가하기]
1. 산점도 그래프에 선형식을 그려보기
sns.lineplot(data=body_df, x='weights', y='pred', color='red')
2. R Square 및 r^2구하기
- 회귀(숫자 맞추는 방법): MSE(수동계산)
- R Square: 평균대비 설명력(0~1)
from sklearn.metrics import mean_squared_error, r2_score
y_true = body_df['heights']
y_pred = body_df['pred']
mean_squared_error(y_true, y_pred)
#10.152939045376309
r2_score(y_true, y_pred)
#0.8899887415172141
3. 한번에 예측값 보기
model_lr.predict(body_df[['weights']])
# = y_pred2 로 지정 후 r^2보기
mean_squared_error(y_true,y_pred2)
#10.152939045376309
#값 같음[심화]
다중선형회귀
# Female 0, Male 1
def get_sex(X):
if X == 'Female':
return 0
else:
return 1
#apply method: 행마다 특정 함수 적용 >> 컬럼 추가
tips_df['sex_en'] = tips_df['sex'].apply(get_sex)#모델설계도 가져오기
model_lr = LinearRegression()
X = tips_df[['total_bill', 'sex_en']]
y = tips_df[['tip']]#학습
model_lr.fit(X, y)
# 예측
y_pred_tip = model_lr.predict(X)
'강의자료 > 머신러닝의 이해와 라이브러리 활용' 카테고리의 다른 글
| 6강. 비지도학습 (07.02) (0) | 2025.07.02 |
|---|---|
| 5강. 회귀, 분류 모델링 심화 및 코드(07.01) ☆☆ (0) | 2025.07.02 |
| 4강. 데이터 분석 프로세스(06.30, 07.01) (2) | 2025.07.01 |
| 3강. 로지스틱회귀(범주/카테고리 분류)(06.26,27) (1) | 2025.06.30 |
| 1강. 머신러닝 개념(06.18) (2) | 2025.06.19 |