비지도 학습(Unsupervised Learning)
답을 가르쳐주지 않고 공부시키는 방법 > 연관 규칙, 군집
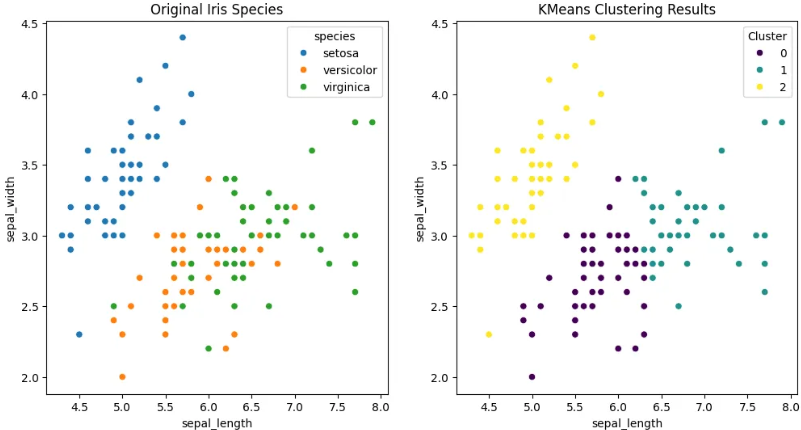
K-평균 군집화/알고리즘(K-means clustering)이란?
1. K개 군집 수 설정
2. 임의의 중심 선정
3. 해당 중심점과 거리가 가까운 데이터 그룹화
4. 무게 중심으로 중심점 이동
5. 다시 가까운 데이터 그룹화(3-5회 반복)
(장점) 일반적이고 적용 쉬움
(단점) 다양한 차원일 수록 정확도 떨어짐, 시간 느림, 주관적, 이상치에 취약
sklearn.cluster.KMeans
- 함수 입력 값
- n_cluster: 군집화 갯수
- max_iter: 최대 반복 횟수
- 메소드
- labels_: 각 데이터 포인트가 속한 군집 중심점 레이블
- cluster_centers: 각 군집 중심점의 좌표
군집평가 지표(실루엣 계수)
실루엣 분석으로 각 군집 간의 거리가 얼마나 효율적으로 분리되어 있는지 측정
- 실루엣 값이 높을수록(1에 가까움)
- 개별 군집의 평균 값의 편차가 크지 않을수록
sklearn.metrics.sihouette_score: 전제 데이터의 실루엣 계수 평균 값 반환
- 함수 입력 값
- X: 데이터 세트
- labels: 레이블
- metrics: 측정 기준 기본은 euclidean
ex. 고객 세그멘테이션(RFM)
- Recency(R) 가장 최근 구입 일에서 오늘까지의 시간
- Frequency(F): 상품 구매 횟수
- Monetary value(M): 총 구매 금액
'강의자료 > 머신러닝의 이해와 라이브러리 활용' 카테고리의 다른 글
| 요약☆ (0) | 2025.07.02 |
|---|---|
| 7강. 딥러닝 (07.02) (0) | 2025.07.02 |
| 5강. 회귀, 분류 모델링 심화 및 코드(07.01) ☆☆ (0) | 2025.07.02 |
| 4강. 데이터 분석 프로세스(06.30, 07.01) (2) | 2025.07.01 |
| 3강. 로지스틱회귀(범주/카테고리 분류)(06.26,27) (1) | 2025.06.30 |