기술 통계의 기본
describe()란?
- 데이터의 분포와 중심경향을 한눈에 파악할 수 있는 핵심 메서드
- 평균, 표준편차, 최솟값, 최댓값, 사분위수 등을 제공해 데이터의 전체적인 모습을 빠르게 이해 가능
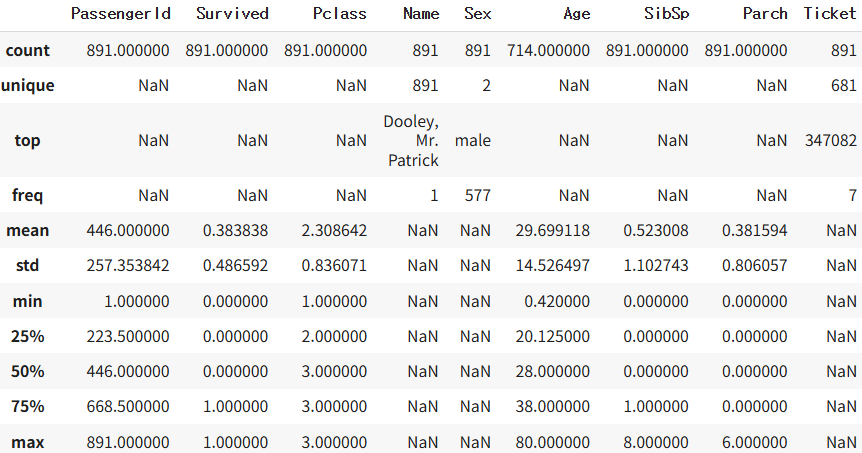
# 기본 기술통계 확인(숫자만 나옴)
titanic.describe()

# 범주형 변수 포함 전체 분석(문자도 나옴)
titanic.describe(include='all')
# Age의 기본 통계 확인
print("=== Age 기본 통계 ===")
age_stats = titanic['Age'].describe()
print(f"평균: {age_stats['mean']:.1f}세")
print(f"중위수: {age_stats['50%']:.1f}세")
print(f"표준편차: {age_stats['std']:.1f}")
print(f"결측치: {titanic['Age'].isnull().sum()}개")
범주형 데이터 분석
value_counts(): 빈도와 비율 이해(불균형이 심한 경우 조정 필요)
분의 형태 파악
- 왜도 > 0: 오른쪽 꼬리가 긴 분포 (양의 왜도)
- 왜도 < 0: 왼쪽 꼬리가 긴 분포 (음의 왜도)
- 첨도 > 3: 정규분포보다 뾰족한 분포
- 첨도 < 3: 정규분포보다 평평한 분포

상관관계 vs 인과관계
- 상관관계가 높다고 해서 인과관계가 있는 것은 X
- 상관관계는 두 변수가 함께 변하는 정도
- 0.7 이상: 매우 강한 상관관계
- 0.3~0.7: 강한 상관관계
- 0.1~0.3: 중간 상관관계
- 0.1 미만: 약한 상관관계
결측치 처리
결측치란?
- 데이터에서 값이 없거나 누락된 상태
- 데이터 수집 과정의 문제: 설문 미응답, 센서 오류 등
- 데이터 입력 실수: 수동 입력 시 누락
- 시스템적 결측: 특정 조건에서 데이터가 수집되지 않음
- 의도적 결측: 해당 없음(N/A) 등
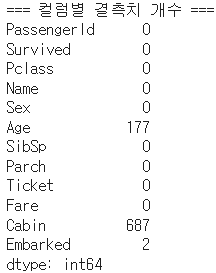
결측치 탐색하기: 어디에, 얼마나 있는지 파악
# 기본 결측치 확인
print("=== 컬럼별 결측치 개수 ===")
missing_counts = titanic.isnull().sum()
print(missing_counts)
이상치 대체하기
df['Defects'] = df['Defects'].replace(9999, pd.NA) #pd(pandas) 결측치 N/A
df['Defects'] = df['Defects'].replace(9999, np.nan) #np(numpy) 결측치 NaN
결측치 제거하기: 언제, 어떻게 삭제할 것인가
1. 행 삭제
- 결측치 비율이 5% 미만일 때
- 결측치 패턴이 완전 무작위일 때
- 충분한 데이터가 남을 때
titanic_dropped_all = titanic.dropna()
print(f"모든 결측치 행 삭제 후: {titanic_dropped_all.shape}") #(183, 12)
print(f"삭제된 행: {len(titanic) - len(titanic_dropped_all)}개") #708개
print(f"데이터 손실률: {(1 - len(titanic_dropped_all)/len(titanic))*100:.1f}%") #79.5%
2. 컬럼 삭제
- 결측치 비율이 50% 이상인 컬럼
- 분석에 중요하지 않은 컬럼
- 다른 변수로 대체 가능한 정보를 담은 컬럼
titanic_dropped_cols = titanic.dropna(axis=1)
print(f"결측치 컬럼 삭제 후: {titanic_dropped_cols.shape}") #(891,9)
print(f"삭제된 컬럼: {set(titanic.columns) - set(titanic_dropped_cols.columns)}") #{'Embarked', 'Age', 'Cabin'}
결측치 대체하기
- 평균값: 정규분포에 가까운 연속형 변수 but. 변수의 다양성 감소
- 중위수: 이상치가 많거나 치우친 분포
- 최빈값: 범주형 변수
- 특정값: 비즈니스 로직상 의미가 있는 값
- 예측값: 다른 변수들로 예측한 값
- Forward Fill, Backward Fill: 시간 순서가 있는 데이터에서 효과적
- 선형 보간법(Interpolation): 연속적인 변화가 예상되는 데이터에서 효과적
- 범주형 변수의 대체 ex. Embarked
# 평균값으로 대체
age_mean = titanic_filled['Age'].mean()
titanic_filled['Age_mean_filled'] = titanic_filled['Age'].fillna(age_mean)
print(f"\n평균값({age_mean:.1f}세)으로 대체 완료")
print(f"대체 후 결측치: {titanic_filled['Age_mean_filled'].isnull().sum()}개")
# 중위수로 대체 (이상치에 덜 민감)
age_median = titanic_filled['Age'].median()
titanic_filled['Age_median_filled'] = titanic_filled['Age'].fillna(age_median)
print(f"중위수({age_median:.1f}세)으로 대체 완료")
# 대체 방법별 분포 비교
print("\n=== 대체 방법별 통계 비교 ===")
comparison = pd.DataFrame({
'원본': titanic['Age'].describe(),
'평균대체': titanic_filled['Age_mean_filled'].describe(),
'중위수대체': titanic_filled['Age_median_filled'].describe()
}).round(2)
print(comparison)
데이터 타입 변환
데이터 타입 확인하기 print(df.dtypes) #object(문자열) > 숫자 계산 및 분석을 위해 숫자 데이터로 변경
1. astype(): 결측치가 있을시 오류
변수_int = 변수.astype(int)
2. pd.to_numeric(): 결측치=NaN으로 변경
df['age_clean'] = pd.to_numeric(df['age'], errors='coerce')

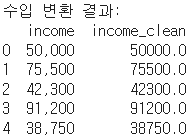
3. 콤마가 포함된 숫자 처리: 콤마 제거 후 숫자로 변경 (.str.replace(): 모든 콤마를 빈칸으로 변경)
df['income_clean'] = df['income'].str.replace(',', '').astype(float)
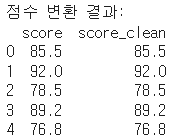
4. 실수형 문자열 변환
df['score_clean'] = df['score'].astype(float)
5. 불리언 타입 변환(Yes/No >> True/False): map()함수 이용
df['is_premium_bool'] = df['is_premium'].map({'Yes': True, 'No': False})

날짜 데이터(문자열>>숫자열)
날짜 형식 통일: pd.to_datetime() >> 숫자열로 변환(계산가능해짐)
orders_df['order_date_clean'] = pd.to_datetime(orders_df['order_date'])

컬럼 생성
df['Year'] = df['Date'].dt.year
df['Month'] = df['Date'].dt.month
df['Day'] = df['Date'].dt.day
'특강 > 전처리 & 시각화' 카테고리의 다른 글
| [전처리&시각화] 5일차(06.04)<fig, ax, seaborn, 색상 및 테마> (3) | 2025.06.04 |
|---|---|
| [전처리&시각화] 4일차(06.02) (2) | 2025.06.02 |
| [전처리&시각화] 3일차(05.30) (0) | 2025.05.30 |
| [전처리&시각화] 1일차(05.28) (4) | 2025.05.28 |